




Категория: Инструкции
Ассемблер для Windows
Рассмотрены необходимые сведения для программирования Windows-приложений на ассемблерах MASM и TASM: разработка оконных и консольных приложений; создание динамических библиотек; многозадачное программирование; программирование в локальной сети, в том числе и с использованием сокетов; создание драйверов, работающих в режиме ядра; простые методы исследования программ и др. Подробнее.
Как известно, программирование на Ассемблере - это написание исходных текстов, которые представляют собой набор команд (инструкций) процессора. В этом разделе публикуются подробные описания инструкций процессоров Интел и совместимых.
Я уже не раз об этом говорил, но снова повторю - вдруг кто не слышал )))
Каждый процессор имеет свой набор команд (инструкций)!
Поэтому, если вы изучите инструкции одного процессора, то это не значит, что вы легко сможете создавать программы на языке Ассемблера. Потому что язык Ассемблера одинаков для всех процессоров (ну почти одинаков). Однако инструкции, используемые в языке Ассемблера, могут быть (и так оно и есть) отличаться в зависимости от того, для какого процессора вы пишите программу.
Кроме того, команды с одинаковым именем могут по разному работать с разными процессорами.
Тем не менее, изучать то язык как-то надо. Поэтому обычно начинают с каких-то основ. Как правило, с изучения основных инструкций, которые очень похожи для большинства процессоров (и микроконтроллеров в том числе).
Набор базовых команд процессораИменно с базовых инструкций лучше всего начать изучать Ассемблер. Такими базовыми командами (инструкциями) являются команды сложения. вычитания и других простых математических операций. А также команды перемещения значения из одного источника в другой (например, из области памяти в регистр ).
Пример инструкций процессора Интел (8086): ADD (сложение), SUB (вычитание), MOV (перемещение) и т.п.
Базовым набором команд процессора Intel можно считать полный набор инструкций процессора 8086, у которого было 116 команд. У современных процессоров команд, конечно, намного больше (хотя это зависит от архитектуры - есть процессоры с сокращённым набором команд, где их всего несколько десятков).
Современные процессоры кроме основных команд имеют ещё и разные расширения, такие как набор команд MMX, которые предназначены для более быстрого выполнения определённых операций.
Вообще это тема очень объёмная и довольно сложная. Поэтому в очередной раз советую вам изучить (причём очень тщательно) какую-нибудь хорошую книгу по Ассемблеру (на этом сайте есть ссылки на такие книги).
Ну а я на этом краткий обзор закончу. Смотрите содержание раздела выше. Описания новых инструкций будут периодически добавляться по мере создания материала. Так что подписывайтесь на новости сайта, чтобы всегда быть в курсе последних событий.



















Все процессоры линеек Pentium Pro, Pentium-2, Celeron и Xeon имеют одинаковую базовую микроархитектуру и по этому признаку относятся к одному большому семейству процессоров P6. Для примера мы рассмотрим микроархитектуру процессоров линейки Pentium-2.
Основная отличительная черта микроархитектуры процессоров семейства P6 - использование алгоритмики "динамического выполнения команд" (dynamic execution), которая построена на основе трех базовых концепций: предсказании переходов (branch prediction), динамическом анализе потока данных (dynamic data flow analysis) и спекулятивном выполнении инструкций (speculative execution).
Предсказание переходов - это концепция, которая реализована не только в микроархитектуре процессоров семейства P6, но и в микроархитектуре ряда других высокопроизводительных процессоров (например, процессоров мэйнфреймов). Суть ее заключается в следующем.
На вход процессора поступает поток инструкций для их последующего исполнения. Инструкции поступают в том порядке, в котором они содержатся в коде программы, исполняемой в данный момент процессором. Как только на входе процессора появляется очередная порция инструкций для исполнения, ее содержимое анализируется с целью найти точки ветвления в исполняемом потоке инструкций и предсказать наиболее вероятные пути (ветви), по которым пойдет обработка инструкций после этих точек ветвления. Инструкции, принадлежащие ветвям с наибольшей вероятностью выполнения, тут же ставятся в очередь на исполнение.
Основная идея всех этих манипуляций заключается в том, чтобы заставить процессор выполнить инструкции, которые принадлежат ветвям с наибольшей вероятностью выполнения, "вне очереди" - то есть не дожидаться того момента, когда очередь на выполнение дойдет до этих ветвей естественным образом (согласно порядку поступления инструкций на вход процессора и, соответственно, контексту выполняемой программы), а загрузить эти ветви на выполнение раньше этого момента. Таким образом обеспечивается более полная загрузка и, соответственно, более высокая производительность процессора.
Конечно, такое преждевременное исполнение инструкций может оправдать себя только в том случае, если алгоритм нахождения наиболее вероятных ветвей работает достаточно хорошо. Действительно, если ветвь угадана неверно, то процессору придется исполнить инструкции, принадлежащие как неверно угаданной, так и альтернативной ветви, проделав тем самым двойную работу. Если бы такая ситуация наблюдалась часто, то использование этой методики было бы невыгодно. Судя по тому, что концепция "предсказания переходов" активно используется производителями процессоров, соответствующая алгоритмика развита достаточно хорошо. В процессоре Pentium II за предсказание переходов "отвечает" Fetch/Decode Unit (модуль загрузки/декодирования инструкций).
Динамический анализ потока данных включает в себя выполняемый в режиме реального времени анализ зависимости инструкций от исходных данных и значений регистров процессора, а также определение возможности исполнения и непосредственное исполнение инструкций в порядке, отличном от порядка их первоначальной постановки в очередь на исполнение (out-of-order execution).
Dispatch/Execute Unit (модуль диспетчеризации/исполнения инструкций) процессора Pentium II может одновременно следить за ходом исполнения множества инструкций и выполнять их в таком порядке, который позволяет оптимизировать загрузку вычислительных ресурсов процессора. В это же самое время Dispatch/Execute Unit следит за целостностью данных, над которыми проводятся вычисления.
Выполнение инструкций в порядке, отличном от порядка их постановки в очередь на исполнение (out-of-order execution), позволяет избежать простоя вычислительных ресурсов даже в том случае, когда в LI-кэше нет данных, необходимых для исполнения инструкции, или между инструкциями есть зависимость данных, и зависимая инструкция не может быть исполнена (например, в результате исполнения инструкции "A" получаются данные, которые используются при исполнении инструкции "B"; соответственно, инструкция "B" не может быть исполнена раньше, чем инструкция "A").
Спекулятивное выполнение инструкций - это способность процессора исполнить инструкции в порядке, отличном (как правило, с опережением) от порядка во входном потоке инструкций (что определяется кодом исполняемой программы), но завершить и возвратить (commit) результаты исполнения инструкций в порядке, соответствующем оригинальному входному потоку инструкций.
В процессоре Pentium II спекулятивное выполнение инструкций возможно благодаря тому, что этап "диспетчеризации и выполнения инструкций" (dispatching and executing of instructions) отделен от этапа "завершения и возвращения результатов" (commitment of results).
Используя динамический анализ потока данных, Dispatch/Execute Unit процессора исполняет все инструкции, находящиеся в пуле инструкций (instruction pool) и готовые к исполнению, после чего записывает результаты их исполнения во временные регистры.
В это время Retire Unit (модуль завершения и удаления инструкций) последовательно просматривает пул инструкций и ищет исполненные инструкции, которые не имеют зависящих от них других инструкций, и следовательно, могут считаться исполненными и готовыми к извлечению из пула инструкций. Найденные инструкции извлекаются из пула инструкций в том порядке, в каком они поступили в очередь на исполнение, результаты их исполнения возвращаются (commited) - записываются в оперативную память и/или в IA-регистры (Intel Architecture registers - регистры общего назначения процессора) и регистры данных математического сопроцессора (FPU - floating-point unit)), после чего инструкции удаляются из пула инструкций.
Алгоритмика динамического выполнения команд, включающая предсказание переходов, динамический анализ потока данных и спекулятивное выполнение инструкций, снимает ограничения традиционного "линейного" подхода, при котором весь цикл исполнения состоял из двух этапов - загрузки и выполнения инструкций, а сами инструкции обрабатывались в том порядке, в котором они поступали в очередь на исполнение.
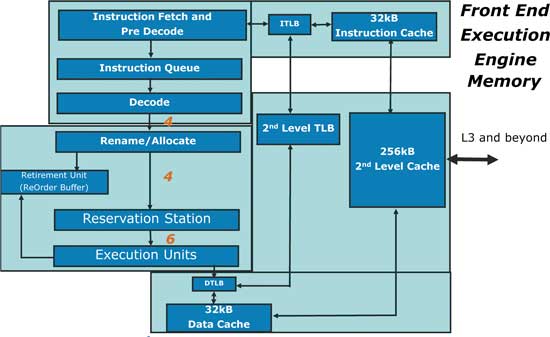
Процессор Pentium II построен на основе семи базовых модулей - Fetch/Decode Unit (модуль загрузки/декодирования инструкций), Dispatch/Execute Unit (модуль диспетчеризации/исполнения инструкций), Retire Unit (модуль завершения и удаления инструкций), Instruction Pool (пул инструкций, его также называют Reorder Buffer - буфер переупорядочивания инструкций), Bus Interface Unit (модуль внешнего интерфейса), LI ICache (LI-кэш для инструкций) и LI DCache (LI-кэш для данных).
Блок-схема процессора Pentium II
Fetch/Decode Unit предназначен для приема входного потока инструкций исполняемой программы, поступающего из LI-кэша инструкций, и их последующего декодирования в поток микроопераций.
Блок-схема модуля Fetch/Decode Unit процессора Pentium II
Этот модуль работает следующим образом. Прежде всего, блок Next_IP вычисляет индекс (порядковый номер) инструкции, содержащейся в LI-кэше инструкций, которая должна быть обработана следующей - то есть извлечена из LI-кэша инструкций и передана для последующего декодирования.
Индекс этой инструкции вычисляется блоком Next_IP на основе поступающей в него информации о прерываниях, которые были переданы в процессор для обработки, возможных предсказанных переходах (предсказание выполняется блоком Branch Target Buffer), и сообщениях о неправильно предсказанных переходах (branch-misprediction), которые поступают от целочисленных вычислительных ресурсов, расположенных в модуле Dispatch/Execute Unit. После вычисления индекса следующей обрабатываемой инструкции LI-кэш инструкций извлекает две строки кэшированных данных (cache line) - ту, которая соответствует вычисленному индексу, и следующую за ней, - а затем передает для декодирования извлеченные 16 байт, которые содержат IA-инструкции (Intel Architecture). Начало и конец IA-инструкций маркируются.
Далее маркированный поток байт обрабатывается сразу тремя параллельно работающими декодерами, которые отыскивают в нем IA-инструкции. Каждый декодер преобразует найденную IA-инструкцию в набор триадных микроопераций (чops) - триадных в том смысле, что микрооперация проводится над двумя исходными логическими операндами, а в результате ее выполнения получается только один логический результат. Микрооперация - это примитивная инструкция, которая может быть выполнена одним из вычислительных ресурсов, расположенных в модуле Dispatch/Execute Unit.
Из трех декодеров два - простые, которые могут преобразовывать только IA-инструкций, требующие выполнения одной микрооперации, а третий декодер - более совершенный; он может преобразовывать IA-инструкции, требующие выполнения от одной до четырех микроопераций. Таким образом, за один такт работы процессора все три декодера могут в сумме сгенерировать максимум шесть микроопераций. Для преобразования еще более сложных IA-инструкций используется микрокод, который содержится в блоке Microcode Instruction Sequencer и представляет собой набор предварительно запрограммированных последовательностей обычных микроопераций.
Полученные таким образом микрооперации передаются в блок Register Alias Table Allocate, где все содержащиеся в микрооперациях адреса IA-регистров преобразуются в адреса внутренних физических регистров процессора семейства P6 - тем самым IA-архитектура и P6-архитекура оказываются развязанными. Это существенно увеличивает возможности работы процессора при вычислениях, так как, во-первых, отпадает необходимость следить за целостностью содержимого IA-регистров при исполнении инструкций, во-вторых, адресное пространство перестает быть ограниченным возможностями IA-архитектуры и может быть значительно расширено, что приводит к росту скорости вычислений, и, в-третьих, такая переадресация обеспечивает возможность спекулятивного исполнения инструкций - далее все вычисления ведутся во внутренней P6-архитектуре процессора, а IA-архитектура снова появляется "на сцене" только на этапе завершения инструкций в модуле Retire Unit.
На этом же этапе к каждой микрооперации как информационной единице добавляются флаги состояния, в которые записывается информация об ее статусе. После этого микрооперации передаются в пул инструкций.
Instruction Pool (Reorder Buffer). Основное назначение этого модуля - предоставить возможность исполнения микроопераций в произвольном порядке; в том числе, отличном от порядка их генерации.
В тот момент, когда микрооперации попадают в пул инструкций, порядок их следования в потоке соответствует тому порядку, в котором они были сгенерированы в результате декодирования IA-инструкций, поступивших на вход модуля Fetch/Decode Unit, - никакого изменения порядка следования пока не произошло. Пул инструкций представляет собой последовательный массив инструкций; при этом любая из этих инструкций может быть в любой момент времени обработана модулем Dispatch/Execute Unit или Retire Unit - то есть порядок обработки инструкций может быть произвольным и не зависит от первоначального порядка, в котором инструкции поступили в пул. Именно поэтому пул инструкций иногда называют еще буфером переупорядочивания инструкций (Reorder Buffer).
Dispatch/Execute Unit. Этот модуль проверяет состояние микроопераций, содержащихся в пуле инструкций, исполняет их, если есть такая возможность, и записывает полученные результаты обратно в пул инструкций.
Блок-схема модуля Dispatch/Execute Unit процессора Pentium II
Reservation Station - основной управляющий блок модуля Dispatch/Execute Unit. Именно он планирует порядок исполнения и занимается диспетчеризацией (распределением между вычислительными ресурсами) микроопераций. Этот блок последовательно просматривает пул инструкций в поисках микроопераций, которые готовы к исполнению - таковыми считаются микрооперации, у которых готовы (т.е. вычислены/загружены) исходные операнды, - и передает (распределяет, диспетчеризует) их на исполнение свободным вычислительными ресурсам, которые могут исполнить микрооперацию. Результаты исполнения микрооперации записываются в пул инструкций и хранятся там вместе с самой микрооперацией до тех пор, пока последняя не будет завершена - этим занимается уже модуль Retire Unit.
Следует подчеркнуть, что жесткого, заранее предопределенного порядка исполнения микроопераций не существует - они исполняются сразу же, как только бывают готовы их операнды и свободен соответствующий вычислительный ресурс. В том случае, если одному и тому же ресурсу может быть одновременно передано на исполнение более одной микрооперации, последние исполняются по принципу псевдо-FIFO (First In First Out) - первой исполняется та микрооперация, которая раньше попала в пул инструкций.
Reservation Station имеет пять портов, через которые организуется обмен данными с пятью вычислительными ресурсами. Поэтому Dispatch/Execute Unit может за один такт исполнить максимум пять микроопераций. Однако при реальной работе с постоянной равномерной нагрузкой на процессор наиболее типична ситуация, когда за один такт исполняется три микрооперации.
Retire Unit - модуль, который знает как и когда завершить (commit) временные внутренние спекулятивные вычисления, выполненные в P6-архитектуре, преобразовать их и вернуть окончательный результат в IA-архитектуре.
Retire Unit постоянно сканирует содержимое пула инструкций и проверяет статус хранящихся в нем микроопераций. Как только находится исполненная и готовая к удалению из пула микрооперация, Retire Unit преобразует результаты ее исполнения, хранящиеся во внутреннем представлении процессора (то есть во внутренних регистрах, в контексте P6-архитектуры), к представлению в IA-архитектуре и записывает результат исполнения в опертивную память и/или в IA-регистры. После этого микрооперация удаляется из пула инструкций.
Тонкость этой процедуры заключается в том, что результаты исполнения микроопераций должны быть возвращены в контексте IA-архитектуры в том же порядке, в каком эти микрооперации были сгенерированы в модуле Fetch/Decode Unit при декодировании входного потока инструкций исполняемой программы.
Ситуация усложняется еще тем, что все это происходит на фоне непрекращающегося потока всевозможных прерываний, точек останова, ошибок предсказания переходов, а также внештатных ситуаций в работе процессора, которые нужно успевать обрабатывать.
Retire Unit процессора Pentium II способен завершить и удалить до трех микроопераций за один такт работы процессора.
Bus Interface Unit. Этот модуль отвечает за обмен данными между LI-кэшом инструкций, LI-кэшом данных, системной шиной и L2-кэшом.
>Да и как об этом ты узнал?
>Посмотрел твой Crysis на видеосистему, заплакал, и выкинул любое сообщение о том, что он работать не будет. Лишь бы ты от него отстал.
>А процессоры тут ни причем.
Он никаких сообщений не выдавал. Он запускался где-то полминуты, потом возникла ошибка, при которой Windows предлагает отправить отчёт. Указывает он на CryRenderD3D*.dll. Запускать пробовал и с 10 Direct'ом и с 9-м. Запустил в отладке в Visual Studio. Он показал на ошибку Illegal instruction. Я нагуглил информацию об инструкции, на которую он указывал. Оказалось, что это 3DNow.
А видеокарта у меня Radeon HD 6310M. Crysis о ней ничего не может знать, так как её не было, когда он вышел. Даже второй Crysis у меня идёт (на низких настройках
>VS 2008 даже не умеет компилировать код используя даже SSE3.
Десятый тоже. Кстати, почему при компиляции с SSE 2 размер exe`шника моей игры вырастает на 20%? Если эти инструкции позволяют работать сразу с несколькими числами, то их должно быть меньше по идее?
>Intel не поддержал AMD в начинании совсем никак и никогда в свои процы поддержку 3DNow! не вводил (поэтому весьма странна твоя история с крайзисом - крайзис работает на интелах, а 3DNow! всегда был как опция, потому поддержка его сейчас и не нужна), а придумал SSE
Значит, 3DNow и MMX никому не нужны, я так понял? Зачем их тогда использовал Crysis? Сейчас запущу Everest, проверю на всех компьютерах 3DNow.
>AMD пошли по пути MMX и заюзали те же регистры, что и MMX, дополнив их системой команд над вещественными SIDM значениями. Таким образом 3DNow! работал одновременно с MMX и они не работали оба одновременно с FPU.
>Залез в лог-файл Crysis`а, вот что нашёл:
Разве может быть такое, что MMX`а нет, а 3DNow есть?
gkv311. у меня как раз тот самый E-350.
Рассмотрим основные параметры МП. Этих параметров окажется больше, чем мы обычно используем для оценки при выборе «сердца» своего «железного товарища». Перечислим основные из них: тактовая частота; разрядность; размер кэш-памяти; состав инструкций; конструктивное исполнение; рабочее напряжение; наличие дополнительных блоков и расширений.
Каждая инструкция, разложенная на микрооперации, выполняется за определенное число тактов1 . Тактовая частота . более правильно ее назвать тактовой частотой ядра процессора – это произведение частоты системной шины ( FSB ), подаваемой от кварцевого генератора на внутренний коэффициент умножения . Умножение частоты происходит с помощью внутреннего управляемого генератора, включенного в контур системы фазовой автоподстройки частоты (ФАПЧ) [5].
Следует различать понятия разрядности адреса и разрядности данных . Процессор выполняет требуемую операцию (инструкцию) над указанными операндами (данными), содержащимися в регистрах . И операции и операнды выбираются из памяти по адресам. Разрядность адреса определяет, сколько битов (16, 32 или 64) используется в регистрах, формирующих адрес данных или инструкций, расположенных в памяти. Разрядность данных определяет, сколько битов используется в инструкциях, оперирующих словами [5].
32-битные регистры позволяют непосредственно адресовать 2 32 = 4 294 967 296 байт (4 Гбайт) памяти. 64-битные 2 64 = 18 446 744 073 709 551 616 байт ≈ 18,4·10 18 (это очень большое число, например, число секунд, прошедших с момента образования планеты Земля равно 10 18 ).
Кэш-память . конструктивно совмещенная с МП, имеет несколько уровней [5]:
Кэш данных первого уровня ( L 1 data cache ) хранит данные, к которым процессор недавно обращался (читал или записывал) при исполнении программы. Кэш инструкций первого уровня ( L 1 instructions cache ) содержит инструкции, недавно выполнявшиеся процессором (они, возможно, повторно будут выполнены снова), а также, инструкции, следующие за этими (упреждающая выборка). Этот кэш имеет маленький размер – от 8 до 128 Кб и очень быстр, т.к. производится только считывание инструкций, что существенно упрощает его реализацию.
Кэш второго уровня ( L 2 cache ) имеет больший размер по сравнению с кэшем первого уровня, но медленнее последнего. Вторичный кэш может быть эксклюзивным – в нем не сохраняются данные и инструкции кэша первого уровня, а может быть инклюзивным . когда во вторичном кэше имеется копия информации кэша первого уровня.
Кэш третьего уровня ( L 3 cache ) применяется не часто, ввиду его дорогостоящей реализации из-за того, что должен быть больше L 2 2.
Конструктивное разделение памяти данных ( L 1 data cache ) и памяти команд ( L 1 instruction cache ), используется в кэш-памяти 1-го уровня в микропроцессорах – это Гарвардская архитектура. В кэш-памяти 1-го уровня возможно совместное расположение данных и команд – это так называемая Принстонская архитектура. В процессорах Pentium 4 кэш устроен несколько иначе.
Набор инструкций или система команд представляет собой совокупность вех команд, которые способен выполнить МП. Инструкции в общем можно разделить на прикладные (используются приложениями для решения конкретных прикладных задач) и системные (используются операционной системой для создания среды, в которой функционируют приложения).
Рассмотрим основные прикладные инструкции процессоров x 86. Инструкции общего назначения – основные целочисленные инструкции х86, используемые всеми программами. Они разделяются на базовые инструкции общего назначения и инструкции 64-битных режимов (доступные для 64-битных процессоров).
Инструкции с плавающей точкой х87 работают с FPU 3 и используются в старых приложениях, требующих точных вычислений. Поддерживается различная точность выполнения инструкций, кроме того, поддерживаются двоично-десятичные форматы данных.
64-битные медиа-инструкции расширений оперируют с данными, расположенными в 64-битных регистрах MMX. Они выполняют целочисленные операции и вычисления с плавающей точкой в скалярном и векторном вариантах и предназначены для медиа-приложений, работающих с блоками данных.
128-битные медиа-инструкции оперируют данными, расположенными в 128-битных регистрах XMM. Эти инструкции предназначены для высокопроизводительных медиа и научных приложений. В потоковом расширении SSE определены инструкции с плавающей точкой одинарной точности (32 бит), в SSE 2 введены инструкции двойной точности (64 бит), в SSE 3 введено 13 дополнительных инструкций, включая SIMD -инструкции с FP -числами двойной точности, целыми числами, а также инструкциями управления памятью и кэшированием [5].
Конструктивное исполнение определяет тип установочного разъема ( Slot – щелевидный разъем, Socket – разъем-гнездо), число контактов (478, 603, 604, 775 - см. таблицу 3.1).
Рабочее напряжение – напряжение питания МП, обеспечивающее его нормальную эксплуатацию и требуемое быстродействие.
Таблица 3.1. Сокеты наиболее популярных процессоров Intel. AMD и VIA
Athlon 64FX, Opteron
Наличие дополнительных блоков и расширений .
БлокFPU присутствует во всех современных процессорах и предназначен для расширения вычислительных возможностей центрального процессора. Он служит для вычисления основных математических функций (тригонометрических, экспоненты и т.д.)
БлокMMX и расширение 3DNow! . Технология MMX используется в 2 D /3 D -графике и коммуникациях. MMX использует принцип SIMD ( Single Instruction – Multiple Data ) – одновременная обработка нескольких элементов данных за одну инструкцию. Технология 3 DNow. 4 содержит 21 инструкцию и впервые была введена в процессорах К6-2 фирмы AMD. Она фактически расширяет возможности, предоставляемые MMX. Эта технология дает существенный прирост производительности при обработке графики, т.е. является мощным дополнением внешних графических ускорителей.
Блок ХММ и расширениеSSE . Расширение SSE ( Streaming SIMD Extensions – потоковые SIMD -расширения) предназначено для ускорения обработки больших потоков данных в формате FP (с плавающей точкой). Это расширение организуется аппаратно в блоке XMM. Блок позволяет выполнять векторные (пакетные) и скалярные инструкции. Векторные инструкции реализуют операции сразу над всем содержимым векторных регистров, а скалярные инструкции работают с одним комплектом операндов.
В процессорах Pentium III появилось расширение SSE. а в Pentium 4 – расширение SSE 2, предназначенное для 3 D -графики, кодирования/декодирования видео и шифрования данных. Последним появилось расширение SSE 3. Блок XMM и расширения SSE. SSE 3 и SSE 3 используются в современных процессорах AMD.
В состав МП Pentium входят следующие основные функциональные блоки: ядро ( Core ); исполняющий модуль ( Execution Unit ); АЛУ ( ALU ); регистры ( Registers ); блок для работы с плавающей запятой ( FPU ) и ряд других.
Все функциональные блоки разделяются на две части: операционную . содержащую УУ, АЛУ и МПП (кроме нескольких адресных регистров) и интерфейсную . содержащую адресные регистры МПП, блок регистров команд, схемы управления шиной и портами.
1 Уменьшая время такта можно повысить быстродействие.
2 L3 cache имеется у процессора Intel Xeon MP, его размер 8Мбайт;






/52435d3ec3d814b.ru.s.siteapi.org/img/58a98c4dd1fbc97dcb8b095341e2eda2e882b987.jpg)